
текст
Лингвисты НИУ ВШЭ создали уникальный «эмоциональный словарь» для обучения искусственного интеллекта
Исследователи Лаборатории языковой конвергенции НИУ ВШЭ — Санкт-Петербург Анастасия Колмогорова и Елизавета Куликова разработали «словарь нового поколения», который позволяет обучать нейросети распознавать человеческие эмоции. Работа демонстрирует трансформацию лингвистики в эпоху искусственного интеллекта


Фото: пресс-служба НИУ ВШЭ, исследователи Лаборатории языковой конвергенции НИУ ВШЭ — Санкт-Петербург Анастасия Колмогорова и Елизавета Куликова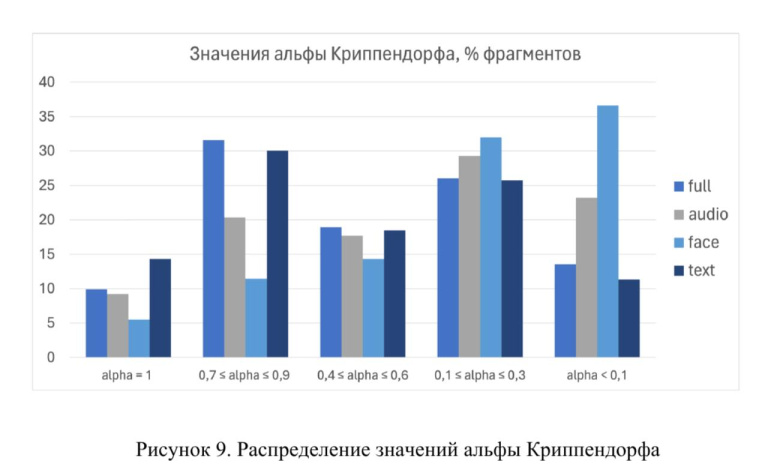
Ученые создали
источник данных об эмоциональной речи для обучения больших языковых моделей
детектированию эмоций на основе признаков из разных каналов коммуникации.
Датасет включает 909 видеофрагментов общей продолжительностью 173 минуты,
каждый из которых оценивался разметчиками по шести базовым эмоциям в четырех
форматах: полное видео, только аудио, только текст и только видеоряд без звука.
«Большие языковые модели могут улавливать скрытые паттерны,
которые мы, может быть, чувствуем на подсознательном уровне, но не можем
формализовать. Наш датасет — это грамотно организованные, хорошо размеченные
данные, приспособленные для работы с нейросетями. То, что раньше делал лингвист
на основе словаря, теперь делают вычислительные модели, только их словарь
должен быть организован по-другому. Вместо пары «слово — толкование»
используется пара «текстовый фрагмент — эмоциональная метка», — объясняет
заведующая Лабораторией языковой конвергенции НИУ ВШЭ — Санкт-Петербург Анастасия Колмогорова.
Исследование
опровергает распространенное мнение о том, что именно интонация помогает лучше
понимать эмоции. По новым данным, люди наиболее согласованно распознают эмоции
при чтении письменного текста и просмотре полного видео со звуком. При
прослушивании речи мнения расходились сильнее, а худший результат показало
немое видео.
Детальный
анализ выявил специфику восприятия разных эмоций: радость и удивление лучше
распознаются через интонацию, злость точнее идентифицируется по тексту (72,9 %
против 67,4 % для аудио), а страх оказался наиболее «вербальной» эмоцией — он
распознается по тексту и аудио в 87 % случаев, но практически не читается по
мимике (всего 3,5 %).
Датасет уже
применяется в реальных проектах. Исследовательская группа использовала его для
анализа отзывов посетителей Владимиро-Суздальского музейного заповедника и
создания эмпатичного чат-бота для Эрмитажа, способного определять эмоции
пользователей и адекватно на них реагировать.
«Раньше для такого анализа нужны были огромные размеченные
выборки и мощные вычислительные ресурсы. Сейчас достаточно показать нейросети
несколько десятков качественных образцов из нашего датасета», — отмечает Анастасия
Колмогорова.
Фото: пресс-служба НИУ ВШЭ, распределение значений альфы Криппендорфа
Кроме того,
разработанный инструмент позволяет оценить качество существующих систем
автоматического распознавания эмоций. Исследователи протестировали восемь
популярных моделей — текстовых, аудиальных, видео и мультимодальных. В
результате эксперимента текстовые модели показали лучшую точность (50-58 %),
аудиальные — среднюю (около 40 %), а анализ мимики — самую низкую (25,6 %).
Словарь для нейросетей доступен исследовательскому
сообществу. Команда Лаборатории языковой конвергенции НИУ ВШЭ — Санкт-Петербург планирует расширять коллекцию и изучать работу со
смешанными эмоциями.
Результаты исследования
опубликованы в журнале «Вопросы лексикографии».
Технологии
Машины и Механизмы
Машины и Механизмы
Всего 0 комментариев

 Механизм успеха: сентябрь 2025
Механизм успеха: сентябрь 2025 Специалисты СПбГУ разработали отечественный инструмент для быстрой диагностики инфекций
Специалисты СПбГУ разработали отечественный инструмент для быстрой диагностики инфекций







